Frequently Asked Questions (FAQ)
Why Linux?
-
Linux offers a very complete system call set which is vital for application portability.
Furthermore, as an open source operating system Linux provides easy access to source
code (useful for understanding details). If necessary, open source Linux may be modified for
custom needs. The Colony project is developing a Linux kernel suitable for very large
node count parallel applications.
What is Parallel Aware Scheduling?
-
Parallel Aware Scheduling is an operating system scheduling strategy that utilizes
a more global view of process scheduling than that of a single node. This is
especially important for large node count parallel applications. As the interactions
among cooperating processes increase, mechanisms to ameliorate waiting within one or
more of the processes become more important. In particular, collective operations such as
barriers and reductions are extremely sensitive to even usually harmless events such
as context switches among members of the process working set. The objective is for
all the tasks to have the same priority across all processors,
and to force other system activity into periodic and aligned time slots during which
the MPI tasks do not actively compete for CPU resources. In this way, the effects of
operating system interference are reduced for synchronous collective calls (e.g.
MPI_Allreduce, MPI_Barrier, MPI_Allgather, ...).
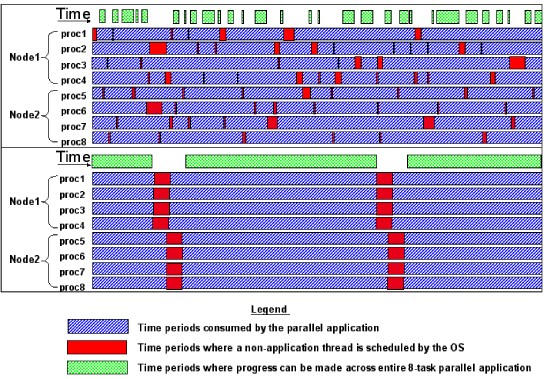
The below figure depicts two schedulings of the same eight-way parallel application. In
the lower depiction, co-scheduling increases the efficiency of the parallel application
as indicated by the larger amount of time periods where progress can be made across the
entire 8-task parallel application. The top legend is blue; the middle legend is red,
and the bottom legend is green.
What are Virtualized Processors?
-
Charm++ and Adaptive MPI are based on the notion of virtual processors: progammers
target their program to a large number of (logical or virtualized) "processors",
independent of the number of physical processors, and the runtime assigns many virtualized
processors (VPs) to physical processors. The programmer chooses the number of virtualized
processors used based on application-structure considerations, while keeping the amount of
work per VP above a minimum threshold to limit the effects of runtime system overhead.
In this way, the programmer is free to pursue the problem independent of the number of processors and effective
parallel progamming is made much simpler. Each VP may just be a C++-style object, but
to program MPI and other applications, a user-level thread can be embedded in such an object.
These user level threads are extremely lightweight and migratable across processors, and
are called "Virtualized Processor Threads". This idea of virtualization is distinct from
"Virtual OS".
What motivated the name HPC-Colony?
-
HPC is a common acronym for High Performance Computing. Today the most capable machines
are massively parallel machines consisting of hundreds of thousands of processors. At
this scale, many issues surface which are not an issue on machines consisting of a few
dozen processors. Colony is working to identify these issues, and to develop strategies
to solve problems associated with very large processor counts.
Colony can refer to a very large group of penguins (pride of lions, gaggle of geese, colony of penguins, ...); it was chosen as a wordplay on Linux's mascot -- Tux the penguin.